
100年前的盲人,怎样读完一本普通印刷书?
拥有正常视觉的人们,看书靠的是光线。白纸比较亮,黑字比较暗,肉眼就在明暗交错之间分辨出了文字。
那视觉缺失的人靠什么来阅读?一种是靠触觉,有盲文书可以摸。一种是靠听觉,当一些书没有翻译成盲文版,说不定还能找到有声读物。
假如现成的有声书也找不到,盲人要怎样读起一本普通印刷书?
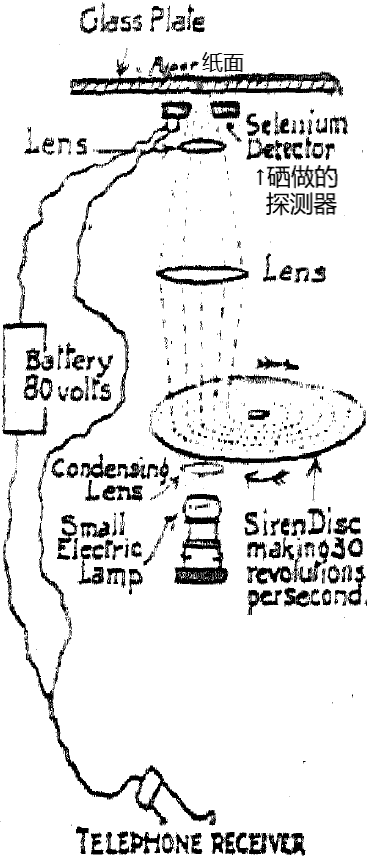
早在1913年,英国伯明翰大学的物理学家埃德蒙·富尼耶·达尔贝(Edmund Fournier d'Albe),就展示过一台帮助盲人听书的扫描仪,取名“Optophone”(光电阅读装置)。几年过后,设备又被一家科学仪器制造商改造成了更实用的版本。
1920年的杂志报道丨Scientific American
用音符“写”字给人听
不同的音符组合,代表不同的字形。比如,字母T有一横一竖,横用一个单音拉长来表示,竖用和弦来表示。这里用到的音符,最高到嗦(SOH),最低到低八度的嗦(SOH)。

字母T对应的音符丨Tiffany Chan
而音符的高低,体现了墨迹在纸上的位置高低:T的一横在最上面,把最高的音符嗦(SOH)拉长即可,而T的一竖由上到下都有墨迹,可以把嗦(SOH)发(FAH)咪(ME)来(RAY)哆(DOH)五个音同时奏响,就是一个和弦。
那么,字母T出现时,耳机里应当先发出连续的嗦(SOH),中间出现一个短促的和弦,最后再回到连续的嗦(SOH)。一个字母,一个单词或是一段话,都可以用一串音符“写”下来:
单词“Type”对应的音符组合丨Tiffany Chan
只要提前熟悉字母和音符串的对应关系,盲人就可以听出一本书的内容了。
把字形翻译成音符,从规则上看并不复杂,但也只是这台机器的一部分工作。而在此之前,它总得先看出书上印着怎样的字形,才能开始翻译。
所以,自动扫描文字,才是重中之重。
硒看得出黑和白
开头说到,肉眼是靠光线分辨纸上的文字。从黑字上返回眼里的光很弱,不像白纸的反光那么强。但机器如何做到类似的感知?
科学家想到了硒,这种物质的电阻会随着光照强度而变化。在硒两边连上电池,当光打在墨迹处,再反射到硒表面,硒的电阻会比较大,通过它的电流就小些;光从纸面的空白处反射到硒表面,硒的电阻会比较小,通过它的电流就强些。
硒两边连着电源,打光和不打光,电流大小不同丨参考文献[1]
光照条件不同,转化出的电信号也不同,这样就可以用硒做光电探测器。当它从左到右扫过一行字,信号强弱会随着黑白交错而变化,这不难理解。问题是,墨迹位置是高是低,比如T那一横在上还是在下,机器怎么知道?
要用不同的光束,扫描不同的位置。假如把一行字分成上下五层,就需要五束不同的光来扫。所谓不同的光,是说每束光打在硒表面,产生一种独有的电信号,区别于另外几束光。这样才能分清,光是从多高的位置打来。

把一行字,分为上下五层丨参考文献[1]
那如何把一束光分成五束不同的光?
这里有个多孔的圆盘,孔一共有五圈。当圆盘以每秒30转的速度旋转,把一束光打过去,透出圆盘的光就被分成了五束,且是五束断断续续(或者说快速闪烁)的光。
多孔圆盘丨Wikimedia Commons、参考文献[1]
光断断续续反射到硒表面,通过硒的电流就会出现波动。而这五束光造成的电流波动各不相同:因为五圈的孔数都不一样,孔越多,光被切断得越频繁,电流波动的频率也越高。
于是有了五束不同的光。让它们分别打在高低不同的位置,便可以根据电流波动的频率,判断光是从高处还是低处反射而来。T的一横在上在下,就不难分辨了。
圆盘把光线分成五束不同的光丨参考文献[1]
用户听到的音符,也是按电流波动频率分配的。
至于要用什么工具来感知电流的波动,电话听筒里的传感器便可胜任。以当时的技术,小到10^-6安培的电流波动都能被检测到。
听到的是黑还是白
机智的你可能发现,照上文描述的原理,电流信号强的是空白处,信号弱的是墨迹处。所以,用户听到的音符代表的不是墨迹,而是墨迹周围的空隙?
1913年的初代产品正是如此,用户没听到的那些音符才表示墨迹的位置。而扫描到单词与单词间的空格时,所有音符还会一起奏响。因此,发明者把它称为“白色发声的光电阅读装置”(White-Sounding Optophone)。
它播放的音符组合太过复杂,以至于用户中的佼佼者玛丽·詹姆森(Mary Jameson)经过训练,平均一分钟也只能读一个单词。但她依然成为了第一个读到普通印刷书的盲人。
1918年,科学仪器制造商Barr & Stroud改进了设备,在光电探测器里加入第二枚硒做的感光元件。光线通过圆盘后,一部分光依然去扫描文字,反射到第一枚感光元件;另一部分光没去扫描文字,直接被转向第二枚感光元件。

多加一枚感光元件丨Popular Science
把两枚感光元件的信号结合起来,就能抵消掉空白部分的信号。如此,耳机播放的音符便代表墨迹,代表字母形状,而空白部分静音了。这个版本也被称作“黑色发声的光电阅读装置”(Black-Sounding Optophone)。
当然,它的优点不止是音符的组合变得简单而已。初代设备的构造比较脆弱,哪怕只是有人从旁重重地走过,一些元件也可能滑到不对的位置,影响正常扫描。改良后的设备要稳定许多。
除此之外,改良后的版本还增加了调节扫描速度的功能,最快5秒、最慢5分钟扫描一行,用户可以根据自己辨识音符的熟练程度来选择快慢。

玛丽·詹姆森在读《瓦尔登湖》丨Blind Veterans UK
玛丽·詹姆森也用上了这种“黑色发声”的改良版。后来,她的阅读速度达到每分钟60个单词。玛丽成为了光电阅读装置的重度用户,从学生时代一直用到晚年。
但对大部分人来说,音符的组合听起来可能还是太复杂。而且,有些形状相近的字母如“u”和“n”,很容易混淆。除了使用门槛,价格也令人却步。1920年的35英镑,大概相当于今天的1500英镑(约合1.3万人民币)甚至更多。
1920年,伦敦一栋房子的平均价格大约320英镑 丨Hillarys
另外,当年英国盲人协会正努力向全国普及盲文资源,而光电阅读装置可能给盲文的推广带来威胁,也就得不到协会的支持,销量一直少得可怜。
不过,商业上不成功,未必代表技术的失败。
谁都可能需要的技术
1949年,美国无线电公司(RCA)的工程师们借鉴了光电阅读装置的原理,为盲人群体制造出一种新的阅读机器。
RCA阅读机器,能播放字母的发音,如“A——”丨参考文献[5]
它也要把光打在纸面,再反射到光电元件上,由此区分字母的形状;它也有个喇叭,负责喊出相应的声音。
不过,发光装置不再是一盏灯加个多孔圆盘,而是阴极射线管;光电元件不再是硒,而是光电管;喇叭喊出的不再是代表字形的音符,而是真真切切的字母。
最重要的是,中间多了一个部件叫“电子分析仪”。它收到光电元件发来的信号之后,要从26个字母里挑出与信号相符的字母,才能指挥喇叭读出来。
一种主流观点认为,这就是世界上第一台能完成光学字符识别(Optical Character Recognition,OCR)任务的设备。
拍照翻译丨AFP
后来,随着计算机技术的发展,OCR算法越来越精密。如今,人工智能/机器学习又为OCR注入了一小撮灵魂。
现在OCR的服务对象,早已不止盲人群体。每个人都可能有那么一刻,需要把图片里的大段文字复制出来,或把外国字符拍下来直接扔给翻译软件。人们甚至会觉得,能用上这样的技术是理所当然的事。
但最初让OCR这个概念成为可能的人,也许还是100多年前发明光电阅读装置的埃德蒙·富尼耶·达尔贝博士。
参考文献
作者:栗子
编辑:Odette

本文来自果壳,未经授权不得转载.
如有需要请联系sns@guokr.com