
加粗几个字母之后,英语阅读速度原地起飞,真的这么神奇吗?
最近,一个名叫仿生阅读(Bionic Reading)的插件引发了大家的讨论。通过将部分字母加粗(大部分为单词首字母或冠词),该插件宣称可以人为制造阅读注视,从而帮助读者集中精神、提升阅读效率。

对比一下,加粗单词后,你读得更快了吗?|Bionic Reading
目前已经有几款阅读器率先用上了这个功能,大家可以自行下载体验。
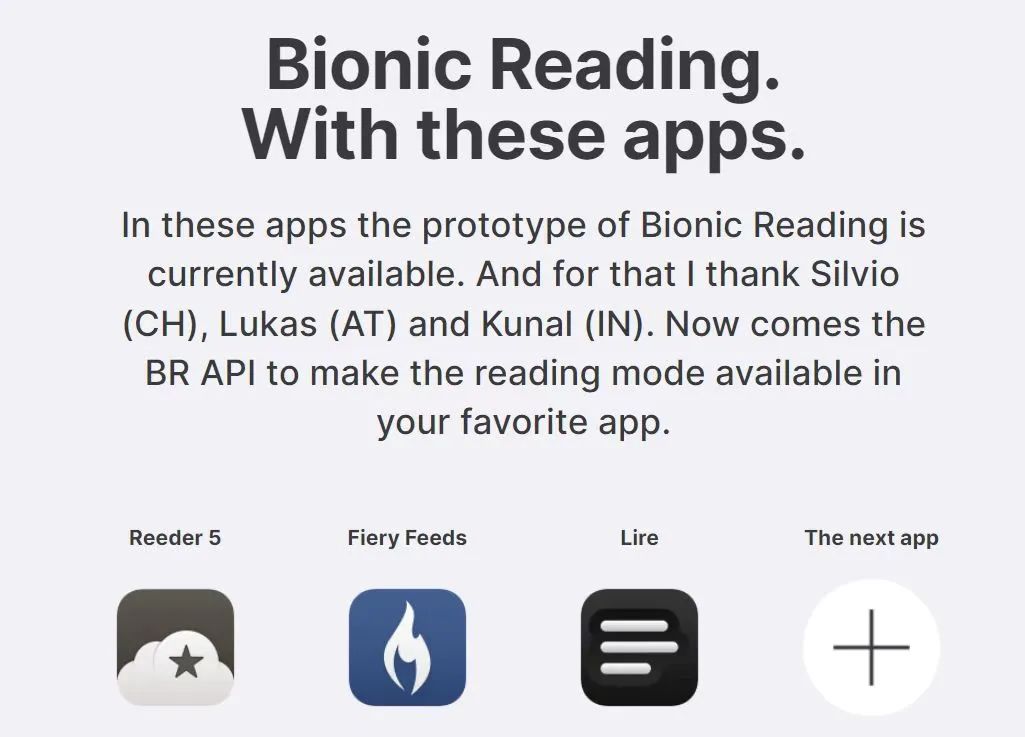
目前支持此功能的阅读器|Bionic Reading
不少朋友对这种“黑科技”相见恨晚,表示装了插件后,自己仿佛习得了阅读秘籍,不跑神了,不迷糊了,一口气读十页不费劲儿,甚至有些“快到停不下来了”。
但我的朋友中也有一些人不买账。比如习惯“扫读”的朋友觉得加粗字体反而碍眼,影响了阅读速度,也有朋友认为仿生阅读的宣传攻势有可能给人过强的心理暗示,造成阅读变快的错觉。此外,在上文出现的对比图中,读者看完左侧的原文后再看右侧加粗过的文本,其实已经是第二遍阅读了,本身就更熟悉内容,自然速度会变快。
所以加粗字体,真的能让阅读速度变快吗?背后有可信的理论支撑吗?
仿生阅读开发者:脑子比眼睛快
打开仿生阅读的官方页面,最醒目的是一行大字“知道吗?你的脑子比眼睛读得快(我们的脑子里已经存储了已知的单词,只要看见部分字母,大脑就能补完整个单词)。”
“脑子比眼睛快”,这句话本身有一定道理。
视觉处理是阅读过程中重要的一环。人从眼睛收到字母的视觉信号开始,到脑中转化出相应的句子意义,这中间是一个复杂的过程,也并不总是按照单一的方式进行处理。
“视觉-阅读”的过程中,有三种基本加工模式:从下至上(bottom-up)、从上至下(top-down)和相互作用(interactive,有时也叫动态交互dynamic interactive)模式。
仿生阅读能提高阅读速度,很有可能是借助了人脑自上而下的视觉-阅读加工模式。在这种模式下,人会优先处理相对较大的知觉单位(比如句子、段落),再分析较小(比如单词、字母)的知觉单位,通过结合上下文,产生对文章的理解。也就是说,人们看到了加粗的字母,就会主动调动以往的经验,“脑补”出剩下的字母,形成自己的假象,并设想下文中的主要内容。
越是成熟的阅读者,自上而下的加工模式往往越强,这也解释了为什么仿生阅读最初目标的受众大多是英语母语者。自上而下模式能解释的“阅读奇迹”并不只有一个。试试这张图,你是不是也能看懂?

中国网友:这不就是中文序顺不响影阅读?还真是。
这张2003年在外网流行一时的图中,不少单词的拼写都被打乱了,但人们仍能阅读、并理解图上的内容,英文水平越高的人,越容易忽略字母被颠倒的顺序。这种现象俗称字母错置效应(Typoglycaemia),最早可以追溯到1976年诺丁汉大学的格雷厄姆·罗林森(Graham Rawlinson)教授的博士生论文。
在他的16组论文实验里,罗林森教授同时招募了成人和小孩,并把被试者们分成了不同的小组,同一小组的人都只能看到同样单词的某几个字母,比如第一组只能看到头1个字母和最后1个字母(1/R/1)、第二组只能看到头2个字母(2/R/0)、第三组改写了单词中了4个字母……最后结果显示,被试者们能不能猜出单词是什么,基本只取决于单词的头尾字母。也就是说哪怕有漏写、错写,读者都能“脑补”出单词本身!
这种“脑补”的能力很大程度上支撑了仿生阅读的速读技术,毕竟在网站的图示中,所有高亮都在单词首字母,网站也宣称自己的技术是“let the brain center complete the word”。
在我个人的使用过程中,还观察到仿生阅读偏向于高亮a、an、the这三个英语冠词。有研究显示,虽然英语冠词本身携带的语义并不多,但它们在句子中的位置能帮助读者识别语法、拆分句子结构,从而帮助视线移动,提高阅读速度。从这个角度上讲,仿生阅读也有一定道理。
不过,在“自上而下”的模式中,“上”或“下”是一个相对概念。相较于字母,单词是更高级的,而相较于单词,句子是更高级的。这也解释了仿生阅读为什么妨碍了习惯扫读的读者。对于这些人来说,可能整体高亮关键词、或者高亮句首、段首会更有用。
读得快有啥用,真的读懂了吗?
虽然仿生阅读在“读得快”上有理有据,但在“深入阅读”上就让人不禁要打个问号了。
从认知心理学来说,流畅度和准确度之间,一直存在着一个权衡效应,读得快未必意味着读得懂、读得好。而对外语学习者来说,阅读更是一件非常消耗脑力的任务,同时关注速度与质量会让工作记忆(working memory)快速消耗殆尽,也就是人们常说的“脑子不够用”,从而导致走神。
再者,目光和阅读之间并不是单一的对应关系。人们日常所说的“眼睛盯着看”在眼动研究中包括了回视频率、回视时间、注视频率、注视概率、平均瞳孔直径等多个研究参数,而阅读则是运用这些参数的一种综合策略。
问一个很简单的问题:当一个人盯着某段文字不动的时候,你觉得ta是在走神呢,还是在深思呢?也就是说,眼动并不能完全代表脑内活动,眼球控制也并完全不代表阅读。从这个角度说,“快到停不下来”也未必是好事。丢掉了那些所谓的“冗杂信息”,文章真的还能保持原意吗?
合上书,马什么梅?
从这个角度来讲,仿生阅读也未必适用于所有文章。沈阳师范大学曾做过一项文本标注对中文阅读眼动的研究。研究显示,虽然添加高亮会指引和帮助参与者们更好地记忆重点内容、忽略干扰内容,但如果含有错误标识或标识过多,那与无标识的阅读效率几乎是一样的。同时,如果阅读的文本是比较简单的内容,那标示也未必可以提高正确率。从这一点上说,经过仿生阅读标识的段落或许是会让你惊鸿一瞥,但这个buff能不能持续,确实还需要繁复检验。
再比如针对不同年龄段,仿生阅读是否需要做出区分?国外不少研究显示,年龄较大的字母语言读者(如英语和德语使用者)会采取一种看似更危险的跳读策略,即更频繁地跳过某些不认识的单词,来弥补自己的阅读障碍。针对这样的群体,单单高亮单词首字母又是否有用?这些都有待进一步实践。
有没有中文的仿生阅读?
在热烈讨论仿生阅读的同时,也有不少网友开始畅想类似的中文阅读神器。如果有,这样的神器应该具备什么样的条件呢?

有人说要加粗偏旁部首,有人说要加粗每个词的第一个字|微博
其实,无论是英语还是中文,母语使用者们都是通过整体字形来识别单词/字的,这也是罗林森博士实验的基础。下图是对外汉语教学常会用到的笔画练习,虽然对于母语者来说轻而易举,但对那些尚未形成整体字形记忆的初学者来说,给这些字填上缺失的笔画却非常难。

作者供图
上文提到过,阅读是一件对工作记忆负荷很重的工作,大脑需要同时输入信息、并提取先前知识。在这个过程中,断句是一件核心工作。与英文长长短短的单词、且词与词之间有空格的隔断方式不同,现代汉语是一个方块字挨着一个方块字的,这就更加重了脑力的负担。从这个角度来说,加粗分词后的第一个字确实有助于帮助断句、加快阅读。
抛开“识字”的层面不说,我国其他关于阅读的研究也不少,有针对字体、字号、句子长度、文字色彩、行间距、分栏等不同方面的,这些辅助阅读的手段的基本思想就是更方便眼睛“录入”,把人的注意力留在文字上。比如《人机工程设计与应用手册》中就有关于字符高度最小适宜尺寸的计算公式。南京大学蒋波博士的学位论文研究发现,对中国大学生而言,把文字分成二栏能减少回视次数,增加注视频率,更适合快速阅读中文。
不过话说回来,美国人搞快速阅读是传统艺能了。上世纪六七十年代,美国电视上就成天播放“伊芙琳·伍德快速阅读课程”(Evelyn Wood Speed Reading Dynamics course)的广告,号称能让人一分钟读2500个单词。不知道当年参加过这个课程的孩子们,现在都还有阅读习惯吗?

当然,伊芙琳的速度也比不上量子波动速读
参考文献
作者:Vanilla
编辑:翻翻
本文来自果壳,未经授权不得转载.
如有需要请联系sns@guokr.com
