
过去,电力是衡量经济的主要指标。现在,算力也将成为衡量经济的另一主要指标。
算力如何改变经济?根据IDC《2021~2022全球计算力指数评估报告》显示,计算力指数平均每提高1点,数字经济和GDP将分别增长3.5‰和1.8‰。
算力也引发了国家的重视。2022年3月,“东数西算”工程正式全面启动,即通过构建数据中心、云计算、大数据一体化的新型算力网络体系,将东部算力需求有序引导到西部,优化数据中心建设布局,促进东西部协同联动。
但,数字化时代降临,摩尔定律放缓,加之算力需求增速明显,传统的单一计算架构已达性能和功耗的瓶颈。
步入数字经济时代,面对海量的多样化数据,如何突破算力瓶颈,如何提升算力与降低功耗之间的矛盾如何解决?英特尔中国研究院院长宋继强在CCF Chip大会上分享了英特尔的心得。
异构计算和异构集成是法宝
“突破算力瓶颈是第一步,通过不同的方式解决多样化数据的计算有效性。提升算力同时考虑绿色计算这个主题是第二步,不能用很耗能的计算方式去解决问题,而是要想如何以能量优化的方式去解决未来的数据处理。”宋继强表示,异构计算和异构集成是解决这些问题的新抓手,灵活组合硬件,能够发挥算力潜能,高效处理复杂计算负载
所谓异构计算就是用不同架构处理不同类型数据。顺着这个思路解决问题,硬件架构就不能偏科,要全面发展。根据宋继强的介绍,英特尔针对不同数据可以拥有不同的处理器架构,如CPU、GPU、IPU、FPGA、AI加速器,它们各自针对不同种类的数据流,包括数据处理的不同特点,可以进行定制。

当硬件堆叠在一起,就需要有人让这些硬件调度好,并根据应用要求跑程序,这时候就轮到软件出场了,但目前这样的软件框架还比较稀缺。英特尔的oneAPI就是充当市场中这种角色,只需让应用者指定程序功能即可,无需非常明确地指定哪些部分运行在CPU上、哪些部分运行在GPU上、哪些部分运行在AI加速器上。“通过底层软件功能模块和工具链,就可以把下面具体的实现分布在不同的硬件上,硬件发生变化,下面具体的实现也发生相应变化,但是上面的软件开发代码不用变。”

做好芯片制程和封装实力要硬
当然,对一个计算系统来说,三个臭皮匠凑不出一个诸葛亮,因此这就要求每款硬件都拥有极强的算力,制程和封装是实现算力的关键。
制程方面,英特尔率先使用下一代基于高数值孔径的极紫外光刻机(EUV),可以进一步降低整个制程工艺的复杂度并提高良率,可以将光刻的特征线宽降低。晶体管供电层面,英特尔会在Intel 20A制程节点通过PowerVia技术实现底部给所有上层的功能逻辑部件供电,把供电层和逻辑层完全分开,可以更有效地使用金属层,以此提高性能。

值得一的是,英特尔未来四年会有五个节点演进。目前已在大量出货的是Intel 7,今年下半年Intel 4就会面世,这是英特尔首次使用EUV的制程节点;明年则会量产Intel 3,在生产过程中会更多地应用EUV;2024年上半年量产Intel 20A后,下半年迅速转入Intel 18A。宋继强强调:“目前在Intel 18A和Intel 20A的研发取得了非常不错的进展,我们感觉这两个节点都会比预期更早地应用到产品中去。”

有了各种硬件,此时面对的一个问题是如何将这些硬件整合到一个系统里,这就需要异构集成,也就是先进封装工艺。该工艺可把不同制程节点的芯片封装在一个大的封装里,同时利用先进封装带来的尺寸、带宽、功耗的优势,让它们不会像原来板级封装一样有很大的延迟和带宽降低。
目前来说,英特尔有两项技术能够实现异构集成,一种是 EMIB(嵌入式多芯片互连桥接),这是一种2.5D封装技术,可以将在平面上集成的芯片紧密连接,将它们之间的凸点间距降低到50微米以下,未来可能降低到45微米、30微米的级别;另一种是Foveros,这是一种3D封装技术,可以将不同计算的芯粒在垂直层面上封装,可以把封装凸点的间距降到36微米,未来还可以继续降到20微米,甚至10微米以下。
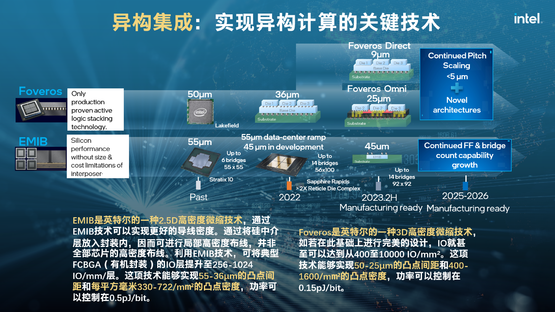
Foveros Omni和Foveros Direct是英特尔在3D封装上未来会使用的两种技术,前者可用通用的方法将不同芯片之间互连的接触点间距微缩到25微米,同时还可以通过铜柱直接为上层芯片供电,和EMIB相比有接近4倍的密度提升;后者是一种更为高级的、不需要焊料、直接让铜对铜键合的技术,可以实现更低电阻的互连,这样的方式可以进一步缩小凸点之间的间距,达到10微米以下。

那么有什么产品是异构集成的吗?宋继强展示了一个非常典型的例子——Ponte Vecchio。它是英特尔目前在高性能计算GPU领域最复杂的SoC,这一SoC共采用了5个不同制程节点的47种不同芯片,有些来自英特尔,有些则来自于台积电。另外,它们在水平层面上用EMIB技术封装,在垂直方向上用Foveros技术进行封装集成。
通过这样的构造制造了专为高性能计算机设计的计算系统,其中囊括了至强处理器和专门的基于Xe架构的Ponte Vecchio GPU,目前用于极光超级计算机。下一代旗舰级数据中心GPU代号将是Rialto Bridge,其内部小芯片采用了更新的制程节点,也会采用最新的封装技术。

更为强大的下一代计算
让算力更强大,除了采用现有的范式,也需要全新的计算模型,神经拟态计算和量子计算是能让功耗暴降1000倍或算力暴增1000倍的秘密武器。
神经拟态计算很大的好处是可以在算法层级和硬件结构设计层级上完全突破现在这种靠堆乘加器的方式来提供算力的模式,而是模拟人类神经元的形式去构造其中底层的计算单元,且大部分是存算一体化。构造出这种芯片,再通过脉冲神经网络的方式编程,实现人工智能的算法。用神经拟态计算消耗的能量与传统CPU或GPU相比减少了一千倍以上,所以这是非常值得关注的。
英特尔的Loihi是神经拟态计算代表性的实验芯片,现在发展到了第二代。Loihi 2基于Intel 4制程工艺,速度比上一代提升了10倍,单个芯片的神经元数量提升了8倍,且面积缩小了一半。具体来说,Loihi 2单芯片神经元数量可达100万。英特尔此前曾将768块Loihi神经拟态芯片集成在5台标准服务器大小机箱中,成为一个数据中心机架式系统——Pohoiki Springs,此系统拥有惊人的一亿神经元。另外,英特尔也提出了一套完整的开源Lava软件框架,去应对神经拟态计算的软件问题。

英特尔在量子计算的研究上持续不断,包含两方面研究。
一方面是应用量子物理效应做传统计算和传统存储的新的器件:采用磁电与电子自旋轨道,将两种器件很好地组合在一起,构造出了MESO的逻辑器件,该技术的突破点在于将多用于存储的自旋电子器件应用在逻辑计算上;通过生产工艺,英特尔将磁畴概念真正在电子器件层面做出实际试验,并且测试得到很好的效果,对于未来在磁畴领域做存储有很重要的意义。
另一方面是大规模量子计算:通过基于硅或硅锗器件,与现在英特尔基于硅的生产工艺非常兼容的技术构造量子比特,这种量子比特都是通过量子阱技术构造里面硅的电子自旋,通过控制自旋的方向,成为量子比特,能够组合起来做大规模的量子计算。

为算力提供支持的研究
“组件研究从来都是英特尔生产、制造、研发部门很重要的一项研究工作,在整个半导体研发学术圈里也非常活跃。”宋继强如是说。
混合键合技术是与Foveros Direct密切相关的技术,该技术研究如何不需要焊接点,而是直接让铜和铜之间键合,并且能达到很高的互连密度的技术。这项技术涉及到产业未来怎么样能够把不同厂家的芯粒很好地封装起来,所以还需要有新的行业标准和测试程序。宋继强介绍道:“因为芯片互连的接触点这么密、这么小,新的测试方法和测试的要求都需要重新制定,和之前差别很大,需要建立起一个新的生态系统。”
CMOS晶体管3D堆叠的研究是与RibbonFET密切相关的技术,通过堆叠CMOS晶体管能够实现30%~50%的微缩。如何选择新的材料去做接触层、构造一些沟道等问题非常重要,可能够进一步提升晶体管的效能。

在硅CMOS基础上,还可以进一步叠加新的晶体管材料和结构,给硅晶体管注入新功能。包括增强模式的高K氮化镓晶体管和硅的FinFET晶体管组合的电源管理技术,下一代嵌入式内存技术相关的工艺反铁电体材料。

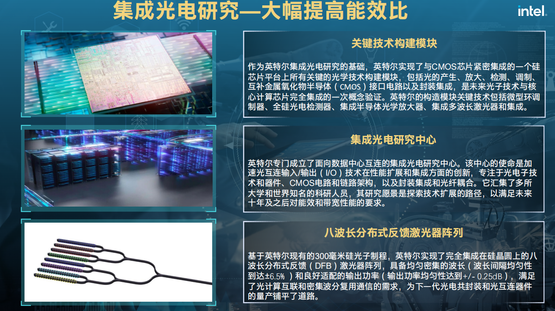
光电是学术界持续关注的问题,英特尔在集成光电方面也有很多的布局和进展。光在通讯时出现带宽高、能耗低的问题,原因在于光电转换效率不高,短距离上不如长距离划算。英特尔在一个平台上实现所有关键模块的集成,光电发射、放大、检测、调制都可以一个大芯片模块中利用CMOS工艺制造,整体尺寸和功耗降低非常多。同时,还涉及到一些基础的器件级的创新,英特尔研制了一个在硅晶圆上8个波长的激光器阵列,这是光的产生部件,它会对光电封装的准确性和能效提升上有很大帮助,并为光电共封装和光互连器件的量产铺平道路。
总结
英特尔的研究不仅覆盖了几年内的计算,也有引领未来的先进计算技术。“从异构计算、异构集成,到器件级创新,再到新的高能效比的架构技术和光互连技术的创新,这些都是为了推动绿色计算领域的发展。我们可以一起去把算力提高千倍,但是依然可以保持整个地球生态的可持续发展。”宋继强如是说。
文/付斌