
想形容那个啥特别那什么,怎么个词来着?点进内文就有答案
“怎么形容春天的生机让人觉得很开心?”
“如何形容消失在人海之中?”
“如何描述夏日暴雨?”
在豆瓣文字失语者互助联盟,超过 30 万人在给自己的语言能力“举哑铃”。越来越多的人患上了这种时代病——不知如何将感受化为文字,或话到嘴边却发现词不达意、言不由衷。在厌倦了网络用语复读机似的轰炸之后,我们如何找回正常的语言表达?
机器有答案。

输入你想要表达的意思,就能获得对应的词语,名为 WantWords(曾叫做“万词王”)的“反向词典”工具拯救了失语的人们。输入“平静中有一点点开心的状态”,就会给出“怡然自得”、“恬然自足”、“泰然”这样的结果,也会让人偶遇一些生僻词汇,像是“塌心”、“姁”、“松范”、“逸豫”,也都表示心情安定愉悦。
系统每次都会给出 100 个词语,背景色由深至浅,代表系统心目中这个词的接近程度。但通常,在前十个词里你就能找到自己想要的那一个(正式研究中,前十个词的命中率是75%)。每天,有两万多用户用它处理失语和词穷的困扰。

图片来源:影视截图
它怎么能“猜”得这么准?
以下为这个反向词典系统开发者的讲解(岂凡超,清华大学计算机系博士生,主要研究人工智能和自然语言处理):
WantWords 的运作原理跟人类的思维模式有些相像。
当人类根据一个描述去猜词的时候,脑子里会经历一个怎样的过程呢?我们常常也不是一下就知道答案的,而是从多个方面,先去做推测。
比如,“ road where cars go very fast ”,车在上面走得很快的路。
乍一看,你可能不知道具体对应的是哪个词,但肯定知道这指向一个名词。英文语境下,你会猜它大概包含 way 这个词素;中文的话,你会猜,这个词很可能包含“路”、“道”等字。
这些信息拼贴在一起,就可以帮助你推断出,它可能是“expressway”、“快速路”、“高速公路”这样的词。
当你在 WantWords 中输入一句话时,我们的模型也会经历一个这样的过程,先分析这句话都体现出词语的哪些特征:是形容词、名词、动词还是副词?它里面有哪些词素?再去找拥有对应特征的词。

expressway 能分离出“快”和“路”两个词素丨受访者供图
看起来,好像只是给输入和输出加了几道筛选条件,但却很有效地弥补了传统反向词典的一些不足。
和人一样,机器也拼阅读量
在此之前,英文世界已经存在多部反向词典。
它们背后的技术,是人工智能领域最主要的分支之一——自然语言处理(Natural Language Processing,NLP),一项旨在让机器理解和说出人类语言的技术。
图灵奖得主, AI 三巨头之一的 Yoshua Bengio(约书亚·本吉奥)曾表示:能否将反向词典任务做好是衡量 NLP 模型学习能力的一个重要的指标。
因为人类的语言表述是多样且复杂的。如今,机器已经能在特定任务上做得很好,比如客服、问答,但如果你只是随便跟它说点什么,它可能就不太理解。
而反向词典本质上就是通过随机的一句话,找到语义相近的一个词。显得机器很懂你。
2000 年,Bengio 提出了“词嵌入”(word embedding)技术,将人类语言转化为机器能够理解的“语言”,也就是数字(词向量)。2013 年, Google 发明的一套工具大幅提高了这个过程的效率。
“词嵌入”为代表的一系列向量表示学习技术赋予了语义的可计算性。根据运算结果,就可以判断两个向量背后的语言单元在语义上的相似性——不出意外的话,离得越近越相似,离得越远越无关。

词向量示意图(意思相近的词语聚在一起)丨受访者供图
本质上,机器并不理解,它只是越来越精确地识别词语之间的相对位置。
就像我们有的时候看书,或者学习一门外语。手边没有词典,不让你查不认识的词是什么意思,但当看到一个词经常出现在特定的上下文之中,久而久之,很多人也能理解它的意思。
我们也会塞给机器大量的文本,随着“语料”喂得越来越多,机器就开始明白:为什么这几个词会连在一起?为什么这个词后面经常出现那个词?
这都是有一些潜在规律的,这就是它的特征。

机器从大量文本中学习丨unsplash
现在这样的语料库很多,最大的包含上百亿个词语。拿着训练好的词向量,去做词语之间相似度的关联是很简单的。
这也是我们实验室在做的事情,训练词向量,拿它们去做应用。但在这个过程中,我们发现了一个问题:对于一些词,机器总是“学”得不太好。
比如低频词,它们在文本中出现的次数很少。出现次数少,对模型来说,就很难准确地学到它的意思。
还有就是一些相关词,可能会有很相近的词向量,因此被机器误判为同义词。
比如“汽车”跟“轮胎”或者“马路”。它们肯定不是一个意思,但因为平时在文本中经常会一块儿出现,这就会让模型误以为,它们是差不多的。
问题还会出现在反义词身上。“我很‘喜欢’这个苹果”,“我很‘讨厌’这个苹果”。你会发现,上下文完全一样啊,那模型就会误以为“喜欢”和“讨厌”是一个意思。
为解决这些问题,就要去借助语料之外的东西了。
以人类的知识约束机器
于是我们就想到,可以人为地加上几层筛选条件,让机器更容易找到那个“正确的”词。
除了词性、词素这两个词语本身具有的特征,我们还加入了两个人为规定的外部特征。
一个叫“层次体系”。这个系统会区分一个词是实体还是概念,实体下面又会分出各种各样的实体。
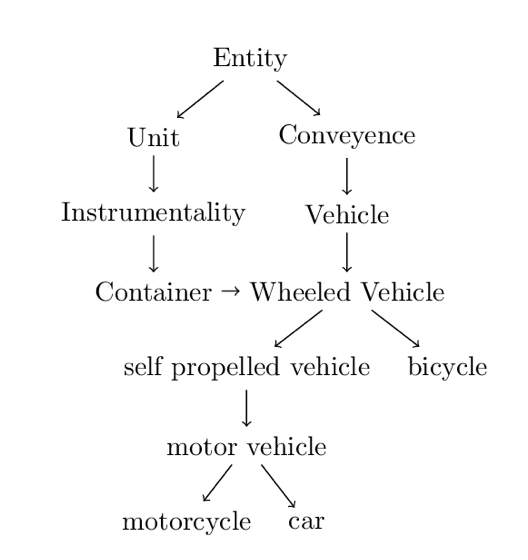
英语词语的层次体系实例丨受访者供图
另一个叫做“义原”。在语言学里,它被定义为语义的最小单位。词是语言学中最小的单位,但从语义上还可以再去拆分。比如“男孩”这个词,它的意思可以被分成“人类”、“男性”、“儿童”。
义原能帮助机器更灵活地表达和理解一个词的意思。像“ expressway ”这个词,它其实有个义原,就是“道路”,还有一个义原是“快”。这两个义原都能在原本的那一句话描述中找到相应的词语。
这四个特征相当于在原本的结果上,又加了很多筛选条件。
回到之前那个例子,“汽车”和“马路”的词向量有点近,因为它们经常同时出现。但这两个词,类别也不一样,义原也不一样,机器就还是能明白:它们是两个不一样的词。

词语的义原标注示意图丨受访者供图
词语的义原信息来自于义原知识库。因为义原并非显式存在,只能由人来定义,有哪些义原,以及一个词应该被标有哪些义原 —— 所以这个过程有点像编词典。
我们使用的 HowNet 义原知识库从上世纪 90 年代就开始构建,“编词典的人”是董振东和董强先生父子。他们在上面投入了十几年的时间,2000 年代初完成第一版并发布,后续不断更新和扩充。
如今,HowNet 已经是一个非常有特色的知识库,也成为中国给世界自然语言处理领域的重要贡献。

OpenHowNet Logo丨受访者供图
2019 年,董振东先生过世,我们实验室主要是我把 HowNet 知识库的构建和维护接了过来,将其开源并重命名为 OpenHowNet。我的主要研究方向之一就是基于 HowNet 去做各种各样的自然语言处理应用。比如,它目前只有中文和英文,我们正尝试将其扩充到两百多种语言。
我的博士论文也与此相关:如何将义原代表的人类知识,与现在深度学习这种纯数据驱动的模型结合起来,来让计算机更能理解人类语言。
义原的应用也为这个时代热议的“人工智能偏见”提供了一种解决思路。
我们当然可以单纯用语料,喂出一个很懂概率,且越来越准确的模型,但数据中那些固有的偏颇是无法通过数据量的堆积而消除的。这种偏颇不是机器的问题,它只是对投喂信息的反馈——当这些信息自带偏见时,机器输出的结果必然也是有偏见的。
当我们用人类的知识给机器加上一层约束,机器就能变好一些。
但人们最喜欢的
仍是同义词替换功能
WantWords 反向词典的第一版产品最早在 2019 年就做出来了,主要由我和实验室的另一名同学张磊合作完成。
在我们思考义原知识库的应用时,发现了这种可能,就去做了探索。这时看到国外有 OneLook (英文反向词典)这样的产品,而国内并没有,就想着可以在研究的基础上做一个演示系统。
一开始真的是一点经验都没有,工程整个就是一塌糊涂。演示系统出来之后也没有做任何推广,只是身边的同学用完反馈说还不错。就这样一直放着,可能一天也才几百不到一千的访问量。
直到去年 11 月的时候,突然被一家科技媒体在微博上推荐,一下子涌进来好多人——当时网站就崩溃了。

科技媒体发博推荐 WantWords丨受访者供图
因为没有人维护,我们也不看微博,崩了三四天都没发现。直到有一家做笔记工具的公司的人联系过来,想合作,我们才知道这件事。
我们当即对服务器进行扩容,同时我们想既然大家喜欢用,可以再去做一些改进,就开始做迭代,调试网页端的各种功能。其实都不是很大的更新,加起来可能最多一个月的工作量,但因为我们都有研究或者工作在身,进度比较慢。
用户量放上来之后,很多人就在后台留言,说很喜欢这个产品。还有人说希望开发 app 、小程序,甚至有志愿者提出说可以帮我们开发。
最开始有人提出愿意帮我们做小程序,后来愿意帮忙的人越来越多,到现在整个志愿者团队已经有 13 个人,有做小程序开发的,有做 app 的。志愿者有来自北京和深圳的前后端工程师,有来自新加坡的设计师,也有在美国的产品经理。

图片来源:微博截图
把它当成一个产品去做之后,我们发现,实际应用时人们的用法跟我们的想象是有差别的。
现在平台每天的查询量有二十多万。从后台数据看,绝大部分人还是在用它查同义词、相关词或者反义词。
虽然我们本意不是想做这个。这个词典更大的价值在于,能根据人们的一句话描述,找到意义对应的词汇。同义词替换本身并没有什么技术含量,很简单的。
但我们也希望它作为产品是好用的。所以在迭代更新的时候,就更加着重满足以词查词的需求。在正在做的新版本里,我们增添了很多好玩的功能。
比如最简单的,你想找 aabb 形式的词(花花绿绿),想找中间包含一个特定字的词,想找表达正向或负向情绪的词;还可以找谐音梗,比如你输入朱广权、李佳琪,词典就能帮你找像“小猪佩奇”这样带谐音梗的词。
同时,我们也支持更多类型词语的查询,包括古汉语词、专业术语、网络流行语等,在将来还会支持日语、法语等其他语言的词语。我们希望将它打造成互联网最好用的查词工具,帮更多人解决词穷的问题。
其实,有的时候机器
已经比人更会说话了
五年前,我选了自然语言处理作为自己的研究方向。当时这个方向当时还没有像现在这样热门,我心想等到毕业的时候,也许就正好起来了。
结果确实如此。尤其是 GPT-3 出现之后,它的应用给整个行业都带来很大的激励。也正是这个领域的飞速进步让我们的“反向词典”能够达到现在的效果。
GPT-3
马斯克创办的 OpenAI 人工智能研究室创建的语言模型,于 2020 年 5 月推出。它利用深度学习生成自然语言文本。文本质量之高,“在硅谷引发一阵寒意”(《连线》),也引发 AI 生成文本的风潮。英国的《卫报》曾发表过一篇完全由 GPT-3 撰写的报道,主题为阐释为何 AI 对人类是无害的。
其实到目前,在很多的语言处理任务上,机器的能力已经超过了人。
有一些专门用于测试语言能力的任务榜单,中英文版本都有,里面有各种各样的问题,比如让你判断两句话是不是表达一个意思,给你前一句话能不能推出下一句话,等等。
让机器跟人分别去做,现在最好的模型做出来的正确率,已经超过人类的平均水平了。

机器做得比人好,早已不是新鲜事|Unsplash
尽管如此,人们还是在不断探索,很多时候,这种探索会走在实际应用的前面。像 WantWords ,它在研究上的意义就远远大于目前作为一个应用系统的意义。
我们老师一直都说,要做面向实际应用的研究。这个过程中会发现很多新的问题,比如查到的词不那么好,该怎么把一些无关的词去掉之类的。
我们在准备的一篇论文,就是围绕第二版反向词典,它使用的又是一套完全不同的原理架构。具体原理嘛,现在还不能透露。
参考文献
作者:翁垟
编辑:卧虫

本文来自果壳,未经授权不得转载.
如有需要请联系sns@guokr.com
