
所以,KTV打分是有几个评委蹲在里面吗?
如果你还有在KTV唱歌的“古早回忆”的话,是不是有过以下经历:
在KTV唱得声泪俱下,歌曲结束系统评分39;飙高音飙到觉得自己邓紫棋第二,结果机器评价说你的声音像腾格尔。
而你朋友鬼哭狼嚎,一个音拖老长;又或者没有技巧,只有嗓门,但得分就是比你高。
面对占据一半屏幕的打分界面,只觉得瞬间兴趣全无,只想一把关掉,安心唱歌。

K歌房里的我|Giphy
而年轻一些的,不知道KTV评分(甚至KTV)为何物的朋友,可能在短视频里刷到过这种神奇场面:本来唱得干涩难听,打开一个叫“声卡”的东西后,突然一键美声,余音绕梁。
不知从何时开始,唱歌也跟“科技狠活”捆绑在了一起,给你打分、给你修音,说你唱得差的也是它,让你一键成天籁的也是它。
作为K歌软件重度用户的作者深有体会。问:我唱得好听吗?从前,作答的是听众反馈;现在,则是屏幕上的那串分数。仿佛只有借助这剔除了主观因素的“第三只眼”,好与不好才有说服力。
但等等,电脑,是怎么听懂我唱歌的?
K歌和评分是怎么走到一起的
1971 年,当日本音乐家井上大佑带着他制造的十台 Juke 8卡拉OK机前往小酒馆时,可能并没有想到,在不到二十年时间里,这些如电子游戏机般的铁盒子将席卷世界,“改变亚洲的夜晚”,乃至为他赢得诺贝尔奖(尽管是搞笑版的)。

改变亚洲夜晚的KTV|wikimedia commons
八十年代正是卡拉OK在日本风靡的时候。约上三五好友,下班后高歌一曲,是当时许多上班族释放压力、宣泄情绪的选择。慢慢地,大家不再满足于录唱,进而追求更高的音质、更舒适的场地、视听结合的享受,以及更趣味的功能——比如,卡拉OK评分。
音乐娱乐的蓬勃发展带动生产商研发投入。1982 年,日本歌乐(Clarion)公司推出首款带打分功能的家用卡拉 OK 机 MW-5000A。随着卡拉 OK 从日本传入亚洲各国乃至全世界,评分系统也跟着漂洋过海,逐渐成为音乐娱乐中脱不开的一环。

卡拉OK机|wikimedia commons
不过,让机器给人类的歌声评分没有那么容易。
K歌评分的主要思路是比对旋律特征,音高和节奏是两项重要指标。用户演唱的旋律特征和原唱越相似,在机器看来则代表着“音准越好”“节奏越对应”,得分就会越高。
做到这些需要三步走:一是根据评分标准,提取原曲的旋律特征,建立标准模板库;二是通过算法提取被评分的干音(设备采集的未经任何后期处理的人声录音)旋律特征;最后,把两者特征相似度进行量化评估,得出分数。
K歌评分三步走
提取原曲旋律、建立标准库,离不开指令型文件MIDI(Musical Instrument Digital Interface)。这是一种编曲界应用最广泛的音乐标准格式,是计算机和电子乐器通用的“语言”。与mp3、wav等波形文件不同,MIDI文件不传输声音信号,而是传递音符、控制参数等指令,以此控制电子乐器发出适宜的声音。

MIDI文件的编辑界面 | 开源软件Aria Maestosa
由于MIDI是计算机可理解的“乐谱”,内含乐曲的标准音符,算法便可以直接从其主音轨中抽取较为准确的旋律信息,如标准的音高音长等。
相较MIDI的信息“直给”,用户K歌干音的旋律特征则需要靠估算得来。首先,要把干音切为一格格短而平稳的声音信号,就像钟表上一分钟被均分成许多秒一样;接着通过算法估计每格声音信号的基音频率(基音指发声体振动中频率最低、一般而言强度最大的振动,它可以决定音高),生成音高序列;此外还要消除噪音,修正可能存在的杂音、错音。
得出分数前的最后一步,便是把原唱和用户歌声的旋律特征进行相似度匹配。简单粗暴的方法是直接计算两段音高序列轮廓的余弦相似度。然而用户歌声的音符和原唱不一定等长,可能影响匹配准确性,于是也有算法会通过线性缩放用户歌声音符长度后再进行比较;或是通过延伸、缩短用户歌声的时间序列,使比较的两者在时间上对齐,再计算相似度等。
你可以通过KTV打分界面上跳动的音符感受到这些步骤,歌声驱动的光标画出的可以看作你的音高轮廓线。只要每个音“高度”适宜,长短合拍,机器就会奖你大大的Perfect。

光标跳动,Perfect出现 | 作者提供
当然,仅凭两个指标很难全面衡量一首歌曲的演唱质量,系统所认定的“高分”演唱在人类耳中并不一定好听。翻翻头部K歌软件的相关话题,总逃不开灵魂呐喊:“我明明唱得很好,为什么分数这么低?!”
从回答数看,大家有很多话想说 | 百度知道
人民群众在长期实践中甚至总结出了一套高分技巧:录音清晰、歌声音量大、声音平稳、尾音拖长,都可能让你获得系统青睐。
至于美妙音色,动情演绎?对不起,不在考虑范围内。
气沉丹田?这机器也懂啊?
唱歌评分需要些新花样。
2012年,在线K歌app唱吧率先把音乐娱乐挪到线上,两年后,背靠腾讯的全民K歌也加入赛道,拉开了在线KTV独占鳌头的时代大幕。主打社交属性、拥有连麦、PK等录唱新玩法的在线K歌逐渐取代线下KTV,成为这一代年轻人的K歌首选。
K歌也PK | 作者提供
在互联网公司技术实力的加持下,K歌评分进入2.0时代。这导致的结果是,靠干嚎骗过机器的难度大幅提升了。
2021年前后,一些K歌软件推出多维打分模型,除了原有的音准、节奏两项,还新增了技巧、气息、情感等几个向度。

多维评分雷达图 | 作者提供
实现思路是拆解各向度的特征,将其转化为可量化的指标。比如技巧中的颤音,这是音高在一定范围内出现的周期性变化,视觉化后反映为音高线类似正弦波形状的上下浮动。
但现存算法的分辨率不如人意,于是有人想到过滤对角化(Filter Diagonalisation Method,FDM),一种源自量子物理,通常被用于研究分子动力学与核磁共振的算法。它能比较精确地把局部基频分解为正弦波,并直接返回其频率和振幅,系统据此判断颤音的存在并检测相关参数。这一跨界让检测准确度比传统方法高了一倍。

带有颤音的频谱图(上)和音高轮廓图(下),音高线抖动部分为颤音 | 参考文献[4]
滑音是另一种常用的歌唱技巧。在算法里,它可以表现为音高线的连续滑动,即音高轮廓图呈现出上行或下行的S形。由于两端有一定的音高差并发生在有限的时间内,音高变化必然伴随加减速,这一过程必定存在两个拐点。通过这些特性找到滑音两个端点,即可辨认滑音。
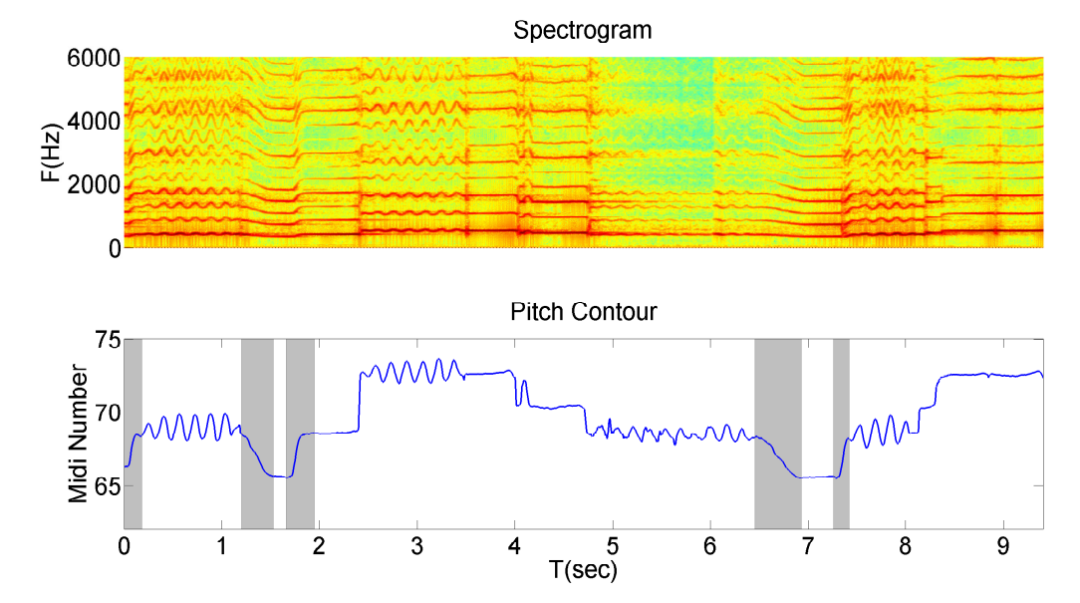
插图:带有滑音的频谱图(上)和音高轮廓图(下),灰色部分是滑音 | 参考文献[4]
声乐讲究的“气沉丹田”,也在音频工程师们的努力下有了标准。比如,一个发声句句末的长音是否唱足了、声音质量好不好、前后变化程度如何,可以作为衡量歌唱气息是否充足、平稳、控制得当的标准。也有人从气口(唱歌时的吸气时刻)入手:如果原唱相邻两个音之间距离超过阈值,则设置为有气口,据此检测用户是否有不合时宜的断句或未唱满的情况。

歌唱气息评分相关专利 | 参考文献[5]
情感这样的主观领域,则被音频工程师们转化为演唱投入程度,并用音频能量来量化。通过测量不同时间尺度的音量特征和强弱起伏情况,算法便读懂了“感情”。

没有感情(上)与有感情(下)的演唱音频波形图,真实演绎“全是感情” | 参考文献[6]
不过,老方法里的提取和匹配旋律特征仍然是核心,这里面也有了技术迭代。以匹配节奏为例,市面上较为流行的做法,要么是直接比对音符长短,要么是匹配干音音高轮廓与原唱的相似度,但这对漏唱、错音或者跑调选手来说都相当不友好。
新提出的计算思路有点类似音乐游戏:首先,检测干音中音量突然变大的点,再辅以纠偏手段,这样基本能判断演唱中每个音符的起始;再根据乐曲风格设置不同长度和权重的得分窗口,只要用户演唱的音符起始点落到窗口内,就视为得分。这样既兼顾了节奏准确,又有了一定的发挥空间。

落点在窗口内距离模板的音符起始点越近,得分就越高 | 参考文献[6]
此外与老方法相比,新方法强调大数据的运用和算法更新,用户的歌声也参与到模型的投喂和训练中。这使得流行音乐依然是各大算法模型评价得最准的项目,而且越多人唱,它评得就越准。
所以下回想挑战机器的评分权威,你最好选首冷门歌曲。
不好听?一键美音走起
更让人欣慰的是,今天的声音娱乐的技术已经发展到,即便你唱歌大跑调,也能一键成天籁,就像某些歌手一样。
这主要通过调整干音的音准、节奏、音色完成。智能修音可以把跑调、杂音的部分修饰掉,除了涉及旋律特征提取和比对,还有节奏对齐、人声变调变速等步骤,让你至少不跑调,跟上拍。
而提升或衰减人声中的不同频段,则能让人声变得悦耳。比如,适宜的40Hz-150Hz低音频段参数,能让人声丰满柔和,150Hz-500Hz中低音频段则与力度、浑厚程度有关,而500Hz-2000Hz的中音频段则能让人声明亮透彻——根据这些发声特点进行调整,再加上混响,原本干涩的录音就能变得圆润丰沛、富有穿透力。
干瘪的声音变圆润 | 作者提供
部分K歌软件甚至声称能基于用户上传的干音音频得到用户音色模型,从而在修音过程中把个人独特的“情感“、“唱法“等也一并模拟(通过上文你应该知道可以如何做到),得到更自然的“裸妆”效果。
柯南的万能变声蝴蝶结也照进现实。说话者身份、性别能被区分,除了依靠基音,主要还因为共振峰分布的差异。对这两者做出改变,我们就可以实现音调和音色的调整。
小黄人和巨人 | 作者提供
正如当初卡拉OK的风靡恰逢经济不景气,在刚度过的疫情三年里,歌唱让人欢乐、让人宣泄,让人找到社会支持,声音修饰也给了更多人展露歌喉的勇气。歌声,逐渐发展出了娱乐以外的社会意义。
而作为普通用户的我,仍旧习惯用歌声自娱自乐,也娱乐他人。至于唱得好听吗?屏幕显示出的那串分数,也许并不那么重要。
参考文献
作者:方点点
编辑:睿悦
封面图来源:Giphy

本文来自果壳,未经授权不得转载.
如有需要请联系sns@guokr.com
