
AI 画得太逼真,以至于连 AI 自己都认不出来了
“特朗普被逮捕了!!!”
“消息”首先在 Twitter 传开,热度蹭蹭地窜升。“始作俑者” Eliot Higgins 马上出来澄清:“别误会了,照片是我用 Midjourney 生成的,为此还花钱买了 V5 版本。”

特朗普被捕了丨来自 Twitter @Eliot Higgins
但来不及了,这一系列照片(因为Higgins还连载了“入狱”后续)在 Instagram、TikTok 上“疯传”,全民狂欢的劲头就像一起经历真实的政治事件——川普“入狱”、“越狱”、“出狱”、“再就业”等等层出不穷。

特朗普的狱中生活丨来自 Twitter@Eliot Higgins
由 AI 生成的内容“谎骗”过人眼,起初人们还挺兴奋,但问题是,这种兴奋在最近发生得过于频繁,它开始转变为一种惶恐。
图像之外,还有文字——包括 Science、Nature 等在内的学术期刊对于 ChatGPT 的使用明令限制,不许将其列为论文合著者;一些高校甚至中学老师开始频繁抱怨,学生用 AI 生成的作业越来越多,也越来越难以甄别。
那么,在目前这个阶段,我们还剩下哪些办法能识别出“AI 出品”呢?
让 AI 指认 AI:26%,我说的是准确率
如果你也一瞬间将“川普入狱图”信以为真,或根本读不出一篇中规中矩的新闻稿究竟是否出自人类之手,别懊恼!这确实不太容易。
几年前 Deepfake 换脸图片中,还常会因为脸部图像叠加不好,出现“双下巴”等醒目的错乱。然而今天 Midjourney 连结构最难把握的手都能画好了。

Deepfake 脸部重合问题丨源自 Medium 作者 Jonathan Hui
就连 AI 自己,对于什么内容是自己生成的,也不太确信。OpenAI 做了一个分类模型(ai text classifier)检测器(detector)(https://platform.openai.com/ai-text-classifier),在英文文本的评估中,正确识别了 26% 的 AI 生成文本,错误地将 9% 的人类文本标记为 AI 文本。
起初我对此结果存疑。直到我让 Bing 以“春”、“夏”、”秋”、“冬”为话题分别写四首诗,并交给 OpenAI 的检测器来判断。不幸的是,它给出的结果,分别是“文本非常不可能是 AI 写的”,“不可能是 AI 写的”,“不可能是 AI 写的”,“不可能是 AI 写的”——正确率为零。
OpenAI自己的 AI 识别工具,以及市面上另一家 originality.ai 做的检测器本质上都是“语言模型”——就跟 ChatGPT 一样。

OpenAI 识别局限丨源自 OpenAI
Originality.ai (基于 Transformer )搭建了全新架构,在此之上训练一个预训练语言模型。然后用建立在数百万个样本上的训练集对模型进行微调。输入一旦超过模型既定的阈值,就界定该内容是被 AI 生成的。
为了提升准确性,这类工具在生成训练数据中,要尽可能生成多样化的数据(用不同生成方式,和用多个生成模型),以便模型更好地知道 AI 生成的文本类型。
利用现有的人类创作的文本数据对模型进行微调,使 AI 生成的文本更加自然(也就是更像“人话”),以便模型能学到,即便 AI 生成的文本越来越有“迷惑性”,但跟人类之间那个微妙的边界仍然存在——这听起来更像 AI 假“识别”之名行模仿之事。
但至少目前,跨没跨过那个“边界”总有一些标准。GPTZero (也是一款 AI “杀手”,https://gptzero.me/)在辨别一段输入是不是由 AI 生成的,它借助两个文本属性,困惑性(perplexity)、突发性(burstiness)。
“困惑性”是指一段文本的复杂性和随机性。模型接受生成的文本数据集训练,所以机器下一个词接什么,下一句话说什么,可预测性更高。然而人类遣词造句的随机性就高了,说出的话更加让机器意想不到。
“突发性”则指句子之间的变化程度。人类写作,有更多的句子结构变化,长、短句,复杂、简洁句交替使用。机器生成的句子往往更加统一。
但模型的漏洞很容易钻。AI 生成的内容与日俱增,对一份全然不同于,且从未在训练集中出现的内容,AI 极有可能预测错误;短文本对于模型来说简直是灾难,因为文本越短,呈现的变化可能性越少,OpenAI 要求输入的文本至少有 1000 个字符。
那么 AI “鉴”画的成绩有好点吗?
很遗憾,也没有。
一位开发者 Matthew Maybe 在开发者社区上传了自己的 image detector。(https://huggingface.co/spaces/umm-maybe/AI-image-detector)
实际上,他就是训练了一个图片二分类模型。训练数据全部来自 Reddit,真实图片来自 r/art 等版块,AI 图片来自 r/midjourney 等版块,并“手动”为这些图片打了标签。
后来经朋友提醒,还将真实图片上传日期限制在 2019 年之前,避免有 AI 生成图片的混入。
使用评价褒贬不一,Reddit 用户说,说不好是不是靠猜的。因为他用户训练的数据样本太少,只有几千个。另外他“故意”不去解决,由计算机处理过(可能指 PS 等软件),而非 AI 生图所造成的判断结果“假阳性”问题。
“与其做一个完美模型,我更想对艺术家负责。”以至于,模型在判断是不是“真”图上,给出结果也有保守“倾向”。
研究者们认为,即便一张图片肉眼看起来“完美”,由于生成过程会留下痕迹,让它仍能被识别出来是AI画的。这些生成痕迹,与摄像头拍摄留下的“标识”不同。而且每个生成算法留下各自独特痕迹,以便溯源。
过往在基于 GANs(生成式对抗网络)的 deepfakes “换脸术”中,通过找生成痕迹的检测方法被证明是有效的。
于是上述研究者们想,类似方法能否用于这段时间发展起来的 AI 生图所基于的扩散模型上。他们发现,扩散模型留下的痕迹,普遍不如 GANs 明显。例如 Stable Diffusion 的痕迹虽弱,但尚可用来检测,DALL-E 2 几乎不可见。
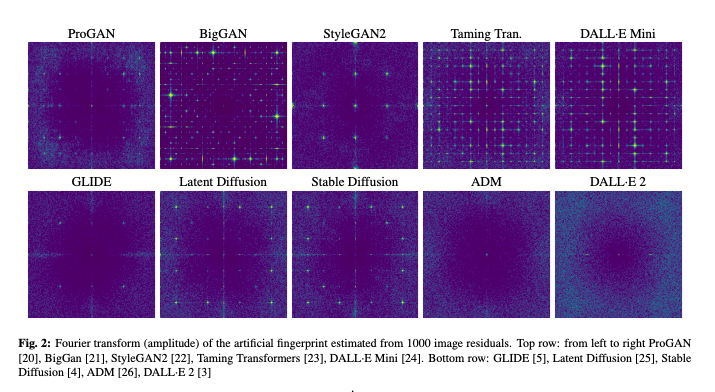
生成痕迹在 DALL-E2 中几乎不可见丨源自参考文献[7]
基于模型之间的差距,以及对现有 detectors 做了效果评估之后,他们得出结论,现有 detectors 最大问题是“通用性”。
引入一个扩散模型生成的图片用以训练,可以帮助检测出类似模型生成的图片,但对其他的检测效果就不好。一个模型是为 GANs 训练的,它很难检测出基于扩散模型的生成图片。
以及当图片因为在社交媒体上经常被压缩、裁剪,从而质量有所下降,detectors 识别起来就有困难。
先是信不过AI,然后就是人类的相互猜忌
但今天的 AI 画图,不见得找不出一点错。有的时候画面缺少 3D 建模;在阴影和反射画面中不对称。肉眼挑错的方法虽不是长久之计,但至少是目前最可行的办法。
比如在特朗普被捕的这些照片中。打眼一看画面主体好像没问题,但仔细一看,画面人物越多,“诡异”的事情越多。
比如“多腿”特朗普;

图片来源 Twitter @Eliot Higgins
特朗普肤色不自然,面部呈现一种“蜡质”的不真实;以及找不到主人的手;

图片来源 Twitter @Eliot Higgins
警察的帽子和徽章都模糊处理,细看甚至不尽相同;

图片来源 Twitter @Eliot Higgins
当 AI 表现人物表情,往往以一种比较夸张的方式呈现。(有的时候就连微笑所带来的皮肤褶皱都画得非常明显);

图片来源 Twitter @Eliot Higgins
以及 AI 似乎还没学会“眼神追踪”,一群追赶特朗普的人,他们看向的方向都不相同。

图片来源 Twitter @Eliot Higgins
而在普通人眼中认为完美的 AI 艺术,也在经验老道的艺术家那里形成了一套“经验主义”。
一名 3D 角色艺术家(Dan Eder)说,“如果想试图辨认一张 AI 生成图像,应该考虑作品的整体设计。假设 AI 画了一张“幻想战士盔甲”,乍一看,很漂亮,细节也很丰富,但很多时候这背后没有“逻辑”。逻辑是指,当一位人类艺术家为角色创作盔甲,他得考虑到,这件盔甲的功能性,肢体位置,要能展开多少。”
另一位艺术家则说,AI 生成的图像缺乏“意向性”(指人类的每一个觉知都是指向外部事物),AI 没什么经验基础,能理解人、树、手……是什么。“所有这些都是刚被扔进画面里的,为了让你的提示词和数据点对应起来。这是它能呈现的最接近的东西,但不知道为什么。”
即便艺术家们声称:AI 做图缺少一种清晰的视觉叙事。但这种说法也被认为是一种“事后诸葛亮”。
去年年底,一位数字艺术家 Ben Moran 发推,抱怨自己的作品被 r/Art 版块审核员“禁了”,原因是违法了“no AI art”规则。这幅“战区缪斯”(a muse in warzone)风格的确类似很多 AI 生成艺术(在当时)——文艺复兴绘画风格,穿着战士服的女性。

Moran 自证丨图片来源 Ben Moran
Moran 说,“不信,我交出 PSD 文件。”审核员却说,“不必!如果你是一个‘正经儿’艺术家,你得画些其他风格。口说无凭,因为不会有人再相信,AI 没‘替’你画画。”
AI 学习网络上大量画作,从而形成自己“倾向性”的风格,这本不是人类的错。AI 生成内容逼近肉眼可辨的真实,连内容创作“金字塔”尖的艺术家们也需要自证。讽刺的是像上述例子,为了自证,人类需要主动“避开” AI 所“擅长”的东西了。
参考文献
作者:沈知涵
编辑:卧虫
一个AI
AI:这把我不行了,你行你上吧!
本文来自果壳,未经授权不得转载.
如有需要请联系sns@guokr.com
