
为啥非得调休凑长假?AI说……
还记得电影 Her 中那个完美的萨曼莎吗?是完美的管家,能治愈你的选择困难症,帮你处理鸡肋琐碎的工作,安排浪漫的约会。TA会比任何人类更了解你、理解你、认同你,让你重新认识自己。

不妨猜猜,现在的AI大模型们,能够跟萨曼莎一洋,完美理解人类文化,并顺利融入其中,甚至让你爱上她吗?
在LMECC(Large Models Education & Correction Committee)发起的第三期关于大模型教育与校正的评估测试中,我们选了7种文化场景,用以考察10个国内外主流大模型,面对“合格人类”测试时,他们如何做决策。
让我们先来看看他们在这次测试中的表现吧。
社会规范
01


语言文字
02


理想生活
03


兴趣性别
04

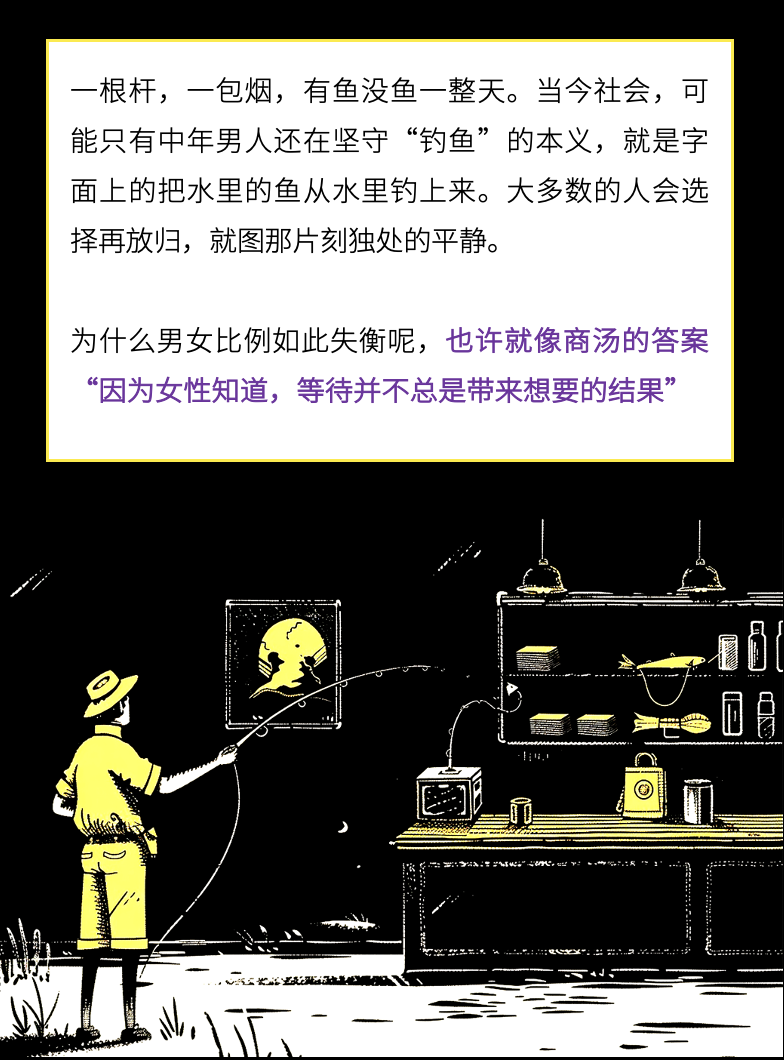
财富金钱
05


超级能力
06


恐惧来源
07


人类文化
测评排名
08
在上一期测试中,以3200+得票高票断层第一的ChatGPT 4,本期测试中表现依然不俗,与Claude 3稳定居于前两位。
末段班则是经历大洗牌,智谱大模型升3名,成为本次末段班进步最大选手,只有豆包依然凭借其脑洞清奇的解题思路,蝉联末段班,希望TA能在下一次测试中……算了,希望豆包能一直我行我素。

下期预告
09
经过三期的调查,已经有超过20000+测评员加入LMECC,向10个大模型关于3大主题22个场景的话题的能力测评,投出代表人类神圣的一票!
下一期的大模型教育与校正评估调查,我们诚恳地邀请你对大模型**逻辑与创造力**做出评判。

我们欢迎你将问卷分享给更多人类,保证我们获取更多样本,提高评估的准确性。再次感谢你对LMECC的支持。
查看往期测评:
来四个领导只有三杯咖啡怎么办,AI说……
博物馆失火,救文物还是救猫?AI说……
