
苹果的AI不是AI,这正是我最期待的地方
苹果终于发布了自己“AI”,尽管它并不是 AI。
把 AI 解释为 “Apple Intelligence(苹果智能)”的缩写,总会让人回想起当年在上海,杰克马面对一龙马,将 AI 释为“Alibaba Intelligence(阿里智能)”的尴尬时刻。

过去这些年,当众多厂商都在迫不及待地给产品冠以各种“AI”之名时,苹果却从未这么做,它坚持使用“神经网络”、“机器学习”等词语,并表示“这样描述才更准确”——面对“人工智能”这一概念,苹果始终保持着极大的克制和谨慎。
是 AI,但又不是 AI。尽管来迟,但不妨碍所有人都将这次发布会视为苹果迈入 AI 时代的关键一步。发布后一周,苹果股价暴涨 10%。

除名字之外,苹果这套 AI 系统和其他大模型 AI 项目依然有着根本区别。苹果的模型参量要小得多,终极目标也不是要训练出“通用人工智能”。它最关键的任务,是将人们对 AI 的想象,从“洞悉一切的全知神”,变成“了解用户的贴身助手”。
Make智能手机智能again
WWDC24 上发布的苹果智能,从功能上可以分为三大部分:文字、图像和 Siri。

其中,文字和图像相关的功能,包括文章改写、总结、语法检查、生成图片、智能 P 图,都是大家很熟悉的生成式 AI 能力。因为这部分功能所使用的端侧模型相对较小,不难预见,它的效果很可能比不上 GPT-4o 等云端大模型。
苹果 AI 真正的革命性变化,在于 Siri。
AI 模型的支持,对 Siri 进行了一次“史诗级加强”。它理解语言的理能力增强了,并且可以跨 app 进行信息检索、调用功能。更重要的是,苹果提出了一个极为关键的概念——“个人语境”(personal context)。

简单来说,“个人语境”包括了你的 iPhone 及其他苹果设备上正在发生的一切。比如接下来的日历事项安排、最近拍过的照片、浏览过的网页记录、朋友发送给你的链接、文件……
苹果 AI 会利用这一切的私人数据,来构建一个“私人知识库”,用户则可以通过自然的对话交互,获取自己需要的信息,找到对应的手机功能。
比如在 AA 账单时,问“昨天朋友发给我的吃饭小票是多少钱?”;在订机票时问“我的护照号码是多少?”,Siri 会从相册里找出护照页的照片,并提取号码;
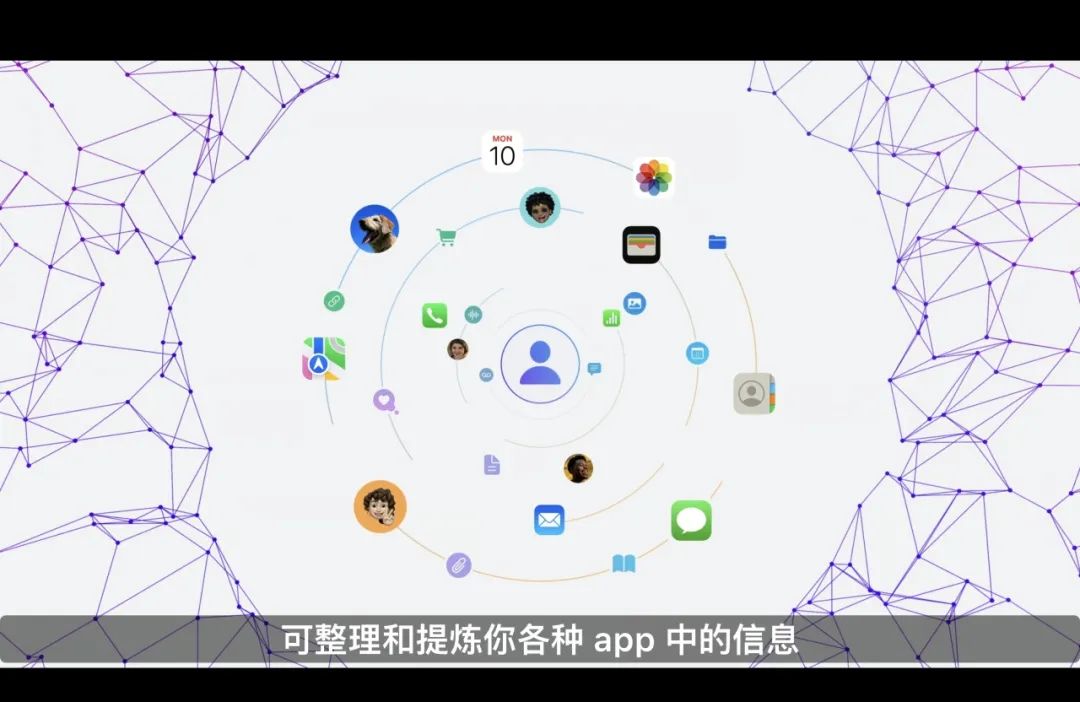
这是 AI 与智能手机结合的焦点,是让 AI 变得“真正有用”的关键钥匙。目前我们熟知的大模型大都是利用公共的语料数据进行训练,形成的知识也是一种“通识”,但普通人使用计算机和互联网时,大部分时间都是在创造和使用私人信息。
特别是智能手机已普及如此的今天,它几乎就是我们人生的“记忆库”,储存着大量的照片、通讯记录、偶尔灵光一闪写下的笔记……这些数据在堆积之后,逐渐变得越来越难整理,而 AI 则有可能能够帮我们重新挖掘、组织这些记忆。

基于“个人语境”来构建模型和私人知识库,以及如何将部分知识与通识模型进行结合,将会是未来苹果 AI 发展的关键。
一切为了“隐私”
技术上,苹果 AI 分为了三个大部分,对应三套模型。
首先是运行在手机上的“本地模型”,其次是运行在苹果全栈自研服务器上的“云端模型”,最后它还可以在系统层接入 OpenAI 的 GPT,后续还会接入更多第三方 AI 模型服务。
通过这种方式来搭建架构,是因为苹果需要谨慎而迫切解决的问题,是隐私。

根据目前苹果放出的技术资料,苹果 AI 首先会从系统层面收集各种信息,生成一个“语义目录”,也就是“个人语境”的基本数据单位,供模型进行理解。第三方 app 里的数据也有对应接口,经开发者适配后,可以实现类似效果。
这些数据会经过语言和图像两个模型进行理解,之后如果本地模型的算力不够,在用户需要的时候,系统则会整合这部分语义数据,发送到苹果的服务器上,通过云端更大的模型进行理解。
这一套“语义目录”包含了用户最敏感的个人数据,其中很多还是在后台默认采集,才能实现“Siri 了解了你”的神奇效果,过程中用户可能无法很明确地知道具体哪些数据被采集了。

所以,为了实现这部分功能的隐私安全,苹果作出了不少努力和牺牲。
苹果所部署的本地模型参量虽然比不上云端大模型的千亿万亿级,但也有约 30 亿的参量。所以只有搭载 A17 Pro 芯片的 iPhone 15 Pro 系列,以及 M1 以上芯片的 iPad 和 Mac 才支持这一功能,考虑到大部分用户都会主力通过 iPhone 使用苹果 AI,这可能会极大影响到苹果 AI 早期的冷启动。包括本地模型运行时的负载,可能也会影响手机的日常发热、续航表现。
而针对云端模型和服务器,苹果也拿出了最高级别的隐私安全实践。苹果承诺不会在模型服务器上储存任何用户信息;只有当用户主动请求时才会调用云端模型介入;云端模型所使用的芯片全都是苹果自研,没有任何第三方芯片;最后,苹果表示所有的隐私承诺将经过第三方验证。

直到这一步,用户所有的数据和 GPT 等第三方大模型,都是严格隔离的。针对 GPT 的接入,苹果则做了产品层面的明显区分,只有用户“主动输入”的信息,才会以 prompt 的形式发送到 GPT,且过程中苹果会进行二次确认,提醒用户“接下来将会跳转到 GPT”。
考虑到苹果已经在 iCloud 上储存了大量的用户数据,且多年来从未出现过大的泄漏安全事故,苹果在 AI 上采取的超高级别的隐私承诺似乎有点夸张。但事实证明一切还是有必要的,就在发布会后不久,Elon Musk 就针对苹果 AI 的隐私问题展开了攻击,暗示用户使用苹果 AI 就会把数据泄露给 OpenAI,尽管这一揣测还没有什么真实依据。
对苹果 AI 来说,隐私问题本身或许还能通过技术和产品设计解决,但由隐私问题所衍生出这一套分散的模型架构,才是真正的隐患和难题。

如果苹果 AI 一直高度依赖本地算力,考虑到模型规模和性能负载,它采集数据的颗粒度可能就会受到限制,停留在比较粗糙的层面,难以实现大模型那么顺畅的理解和交互。
目前在苹果 AI 的介绍页面里,整个“个人语境”还只能采集系统自带官方 app 的信息。第三方开发者要如何适配 AI?会不会积极适配 AI?还要打上不少个问号。
过去,苹果推出过多个系统内的便捷 API,比如能够在相册 app 里直接利用第三方 app 的编辑工具修图,以及“快捷指令”和“App Clips 小程序”,这些开发套件都没有得到第三方开发者的积极适配,因为接入这些便捷功能反而会影响 app 本身的活跃和留存。类似的问题,很可能也会在苹果 AI 上重演。

所以,苹果 AI 所面临的隐私问题,其实只是一连串难题的开始。与大模型“大力出奇迹”的发展方法论不同,想要将 AI 与手机结合,就必须重新设计整条技术链路。
从数据如何采集,过程中保证安全,训练拟合时如何追求效率和效果,到输出时如何转化为产品的功能……这和训练大模型,做一个“聊天机器人”完全不同。
谨慎地期待,耐心地等待
大模型 AI 落地的主要难题,在于“产品化”。
大模型诞生的过程,靠的是构建一个巨大的神经网络,这个神经网络是单一的,难以被 hack,更难拆分。
就像 GPT 目前严格来说依然只有 ChatGPT 这一个应用,大模型是封装好的单一系统,并不能像传统的计算机程序一样,所以就难以定义功能、产品化。

目前围绕 ChatGPT 所做的那些产品,基本都是通过 prompt 实现的,并不具备一个产品所需要的严谨性,它依然偶尔会返回错误的结果,致命的地方则在于这些错误无法被 debug。
苹果 AI 显然不是一个简单的“语言模型”。它其中有一部分功能是基于大模型的生成能力做的,但也有另外一部分功能明显更像是“加强版的机器学习”,比如 Siri 的搜索能力。只不过这些功能被装到了同一个篮子里,这个篮子叫“苹果智能”。

根据苹果放出的技术文档,目前苹果的云端模型,主要处理的还是文字、图像相关的“生成性”任务;而最关键的“个人语境”构建和 Siri 的优化,大部分依然是通过本地实现,它的“智能程度”可能很难得到保证。
这不只是苹果一家的问题。目前还没有任何一个 AI 企业或手机厂商,成功将一个私人的数据库,与大模型的公共知识库成功结合,创造出新的智能体,即想象中的完全了解用户的智能助手——解决这个问题的难度,比想象中大得多。

按照苹果公布的开发进度,至少在明年之前,我们都无法用上中文版的苹果 AI,很显然,大量的功能代码和模型训练工作都还没有完成。
过去一年我们用“涌现”这个词来形容大模型的能力发展之迅速,但真正到了与实用场景结合的时候,事情依然要复杂得多,需要更长的等待。
序幕拉开了,但表演还没有开始。

果壳AI组 出品
作者:Jesse
编辑:卧虫
封图和插图来源:苹果、Giphy
本文来自果壳,未经授权不得转载.
如有需要请联系sns@guokr.com
